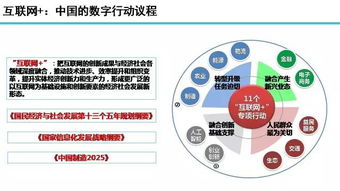
2019年,福州大學成功舉辦了第五屆“互聯網+”創新創業大賽復賽以及垂直領域項目路演系列的第四站,聚焦于互聯網文化領域。此次活動旨在激發大學生創新創業熱情,推動互聯網與文化產業的深度融合。
活動回顧:
本屆大賽吸引了眾多優秀團隊參與,復賽階段競爭尤為激烈。參賽項目涵蓋了數字媒體、在線教育、文化創意、虛擬現實等多個互聯網文化子領域。例如,有團隊開發了基于AR技術的非物質文化遺產展示平臺,讓用戶通過手機即可沉浸式體驗傳統工藝;還有項目專注于搭建高校文化社群,促進校園文化的線上傳播與互動。這些項目不僅技術前沿,更體現了對文化傳承與創新的深刻思考。
在垂直領域項目路演環節,第四站特別邀請了行業專家、投資人和企業家作為評委,對項目進行現場點評與指導。選手們通過精彩的路演展示,分享了項目的商業模式、市場前景和社會價值。評委們從技術可行性、文化影響力和商業潛力等多角度提出建議,幫助團隊優化方案。現場互動熱烈,不少項目獲得了投資機構的初步關注。
活動還設置了交流環節,為參賽者與業界人士搭建了合作橋梁。通過這次大賽,福州大學進一步強化了創新創業教育,培養了學生的實踐能力與團隊精神。未來,學校將繼續支持此類活動,助力學生將創意轉化為現實,推動互聯網文化產業的繁榮發展。